Videometer多光譜圖像分析在種子種質庫管理中的應用
摘要:我們提出了一種多光譜種子表型分析方法,作為管理種質庫種質的快速而強大的工具。使用多光譜視覺系統拍攝 20 種不同水稻品種(每個品種約 30 粒種子)的種子圖像。 然后從圖像中提取特征信息。 特征數據的多變量分析用于根據種質對種子表型進行分類。 正確分類的水稻種子比例為93%。 我們得出結論,多光譜圖像分析可以在比較傳入種子與現有種質、識別種子樣本中的不同種子類型和/或檢查再生種子是否與原始種子匹配方面發揮作用。
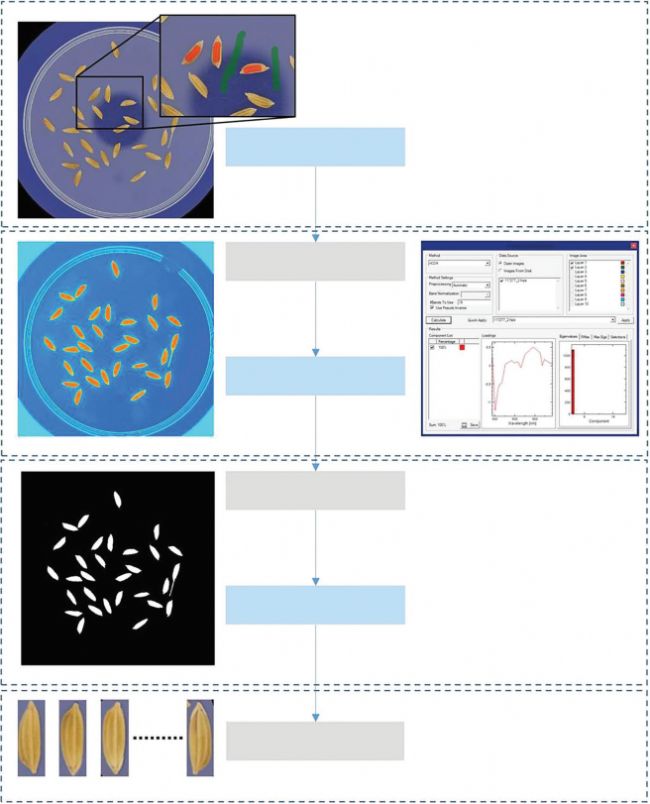
圖1.Blob檢測
使用VideometerLab 3.0版軟件,將圖像(即包含種子圖像的培養皿)標記為具有背景(培養皿)和前景(種子)的區域(圖 1(a))。然后使用典型判別分析 (CDA) 計算屬于兩個不同類別的像素光譜的協方差矩陣之間和內部,創建用于分割(識別圖像中的種子)的評分圖像(圖 1(b)) ;圖 1(c))。在分割之后,我們最終得到了 20 個種質的總共 598 個二元標記對象(BLOB),每個都包含一個單獨的水稻種子(BLOB)(圖 1(d))。
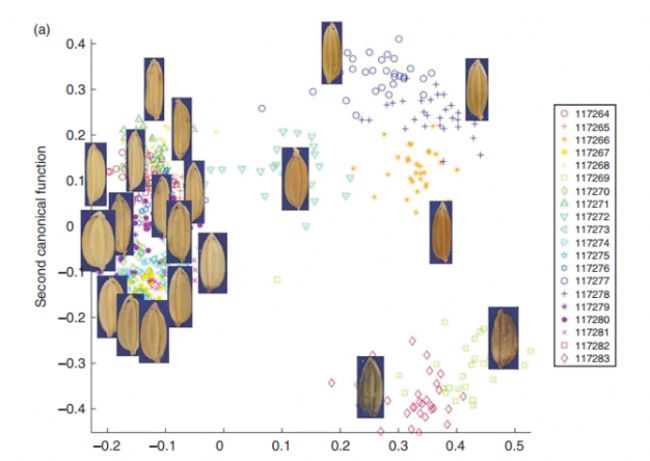
第一個規范函數

真正的IRGC登錄號
圖2.(a)前兩個 CDA 函數的散點圖,覆蓋了種質的示例大米圖像。框中顯示的數字是國際水稻基因庫收藏(IRGC)登錄號。 (b)應用優化模型后得到的誤差矩陣。沿對角線的陰影數字表示 BLOB(水稻種子)的數量被正確分配(預測類別 ¼ 真實類別)。其他數字顯示 BLOB 的數量分配不正確。正確分類種子的總比例為93%。
從每個BLOB中提取的177個特征集合被放入一個矩陣 X∈R598x177:其中一些特征與水稻種子在不同波長下的反射值有關,一些是(線性)CDA 投影,用于區分和增強整個種子和形態的顏色差異。每個特征都通過對所有種質的成對測試進行測試,并且沒有顯示出分離能力的特征被移除。這將特征數量減少到 90。由于與其他特征的高度相關性,另外50個特征被移除(r>0.99;P <0.05),產生一個矩陣 X∈R598x40。
Matlabw Release 2014a (MathWorks, Natick, MA, USA) 用于建模,使用 k-最近鄰 (k-NN) 分類器結合多類 CDA。使用交叉驗證方案來驗證模型,其中將數據分成 N 個相等的部分,并使用比例 (N 2 1)/N 的數據迭代地創建模型。該模型使用剩余的 1/N 數據進行驗證。在迭代過程中,累積了所有 N 個測試部分的分類率的預測性能。對 k ∈[1, 30] 和 N∈[2, 50] 的每個組合進行分析。分類錯誤最少的k和N的最佳值分別為6和13,分類錯誤為 7%(圖 2)。